Behavior-cloned diffusion policies are expressive but remain vulnerable to covariate shift:
small deviations from demonstrated states can compound into task failure. Existing methods
address this either by expanding the training distribution through expert corrections or
synthetic augmentation, or by steering a frozen policy at test time with guidance from a
learned model. The former can be expensive or assumption-dependent, while the latter discards
the corrected trajectories after execution.
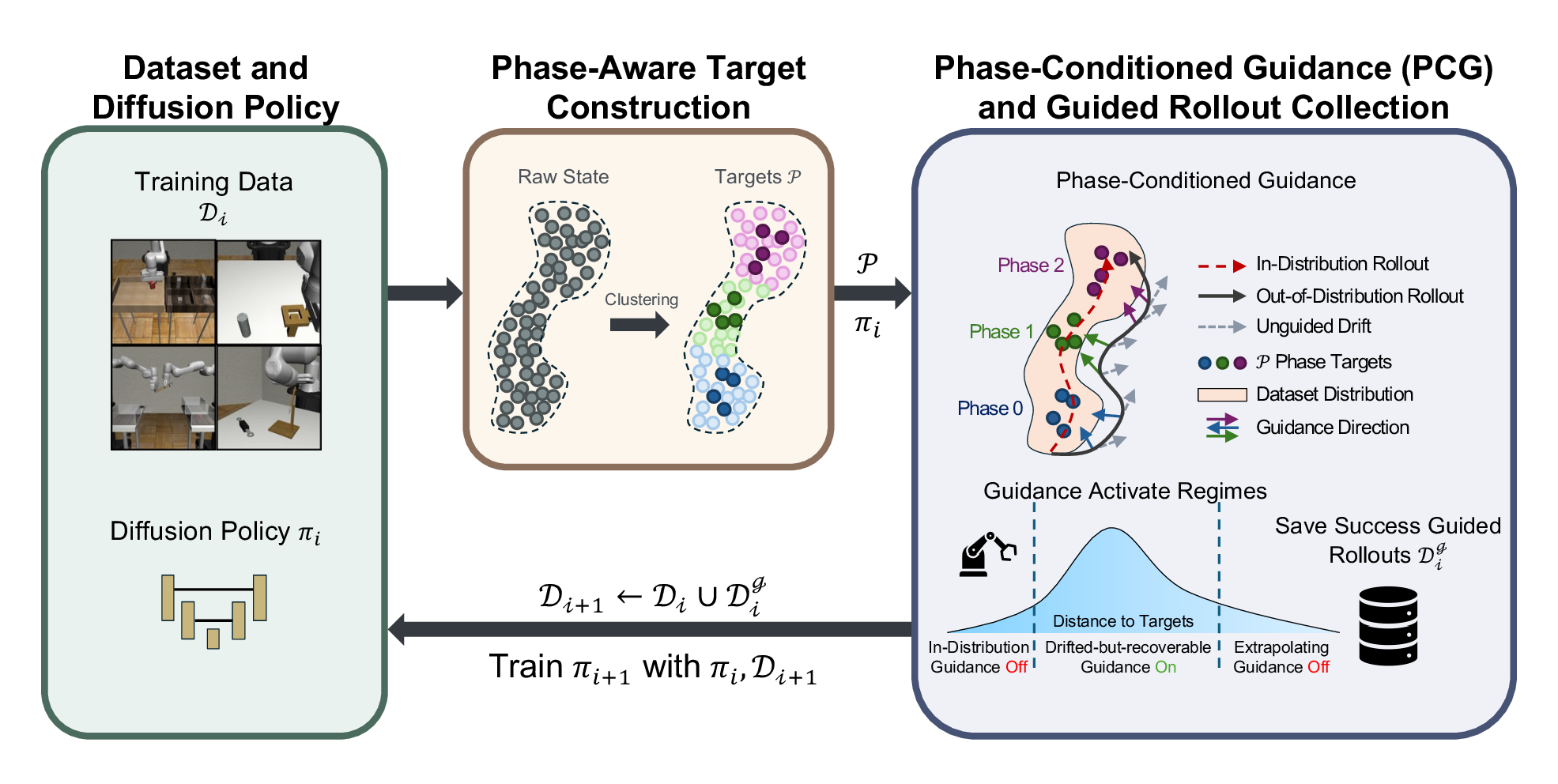
We introduce ReGuide, a self-improving framework that treats guided rollouts as reusable
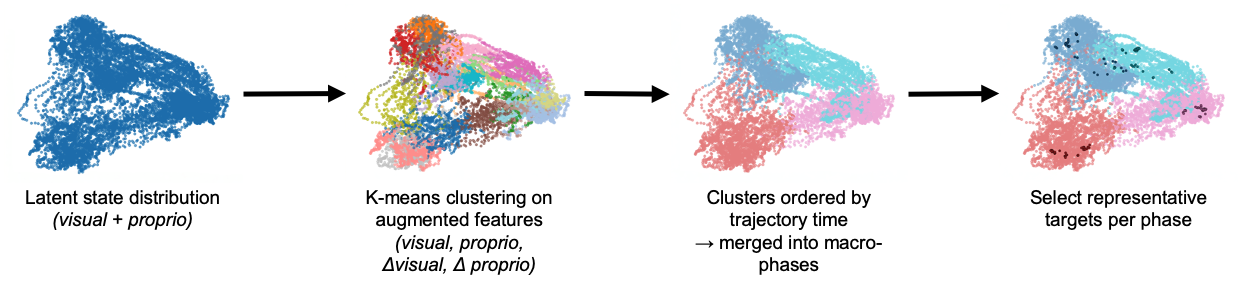
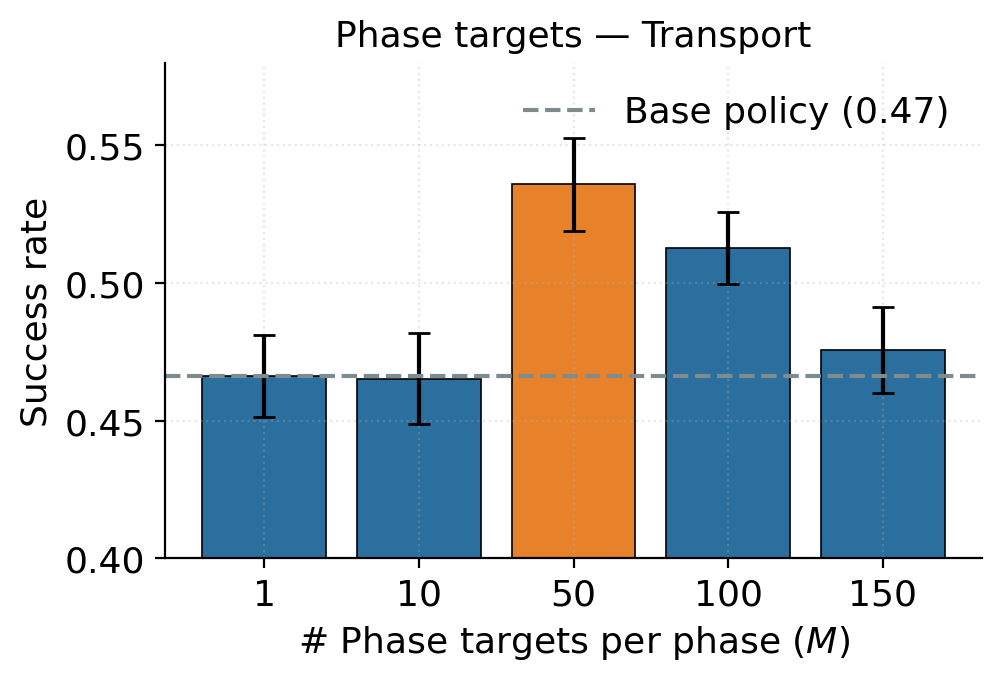
on-policy recovery data. ReGuide first uses Phase-Conditioned Guidance (PCG) to generate
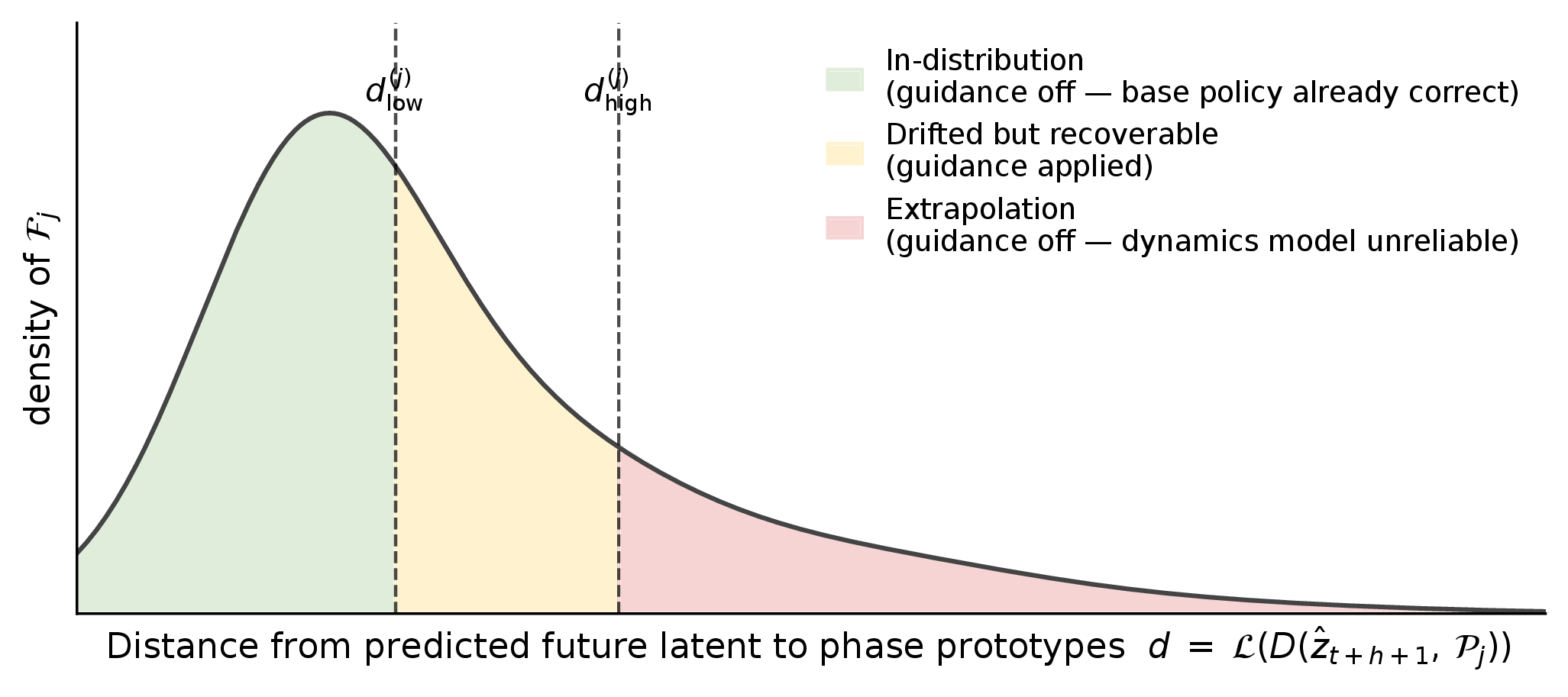
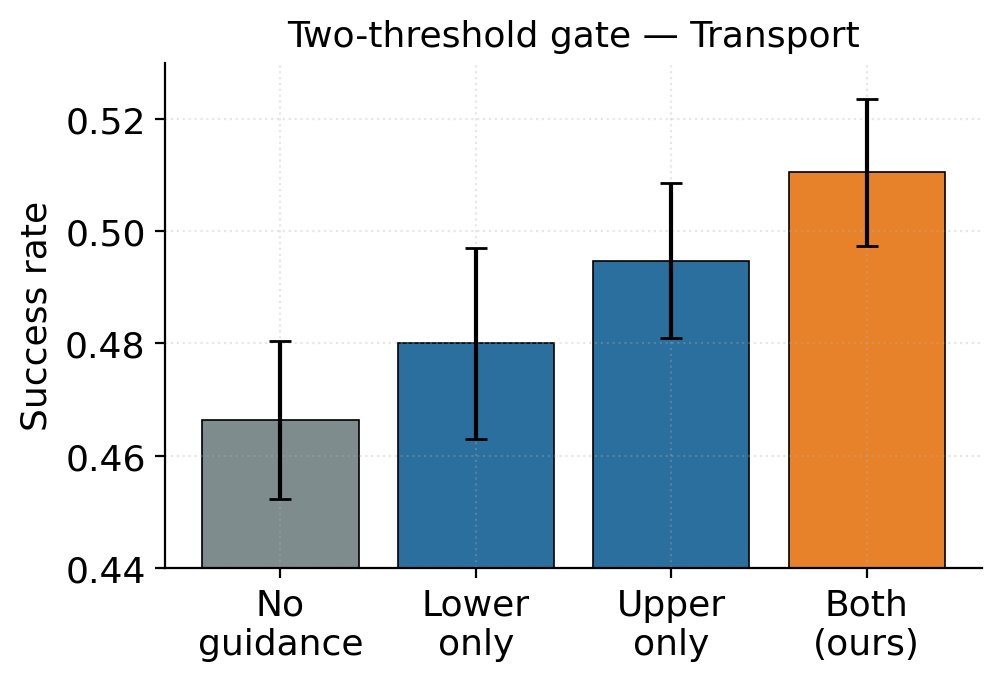
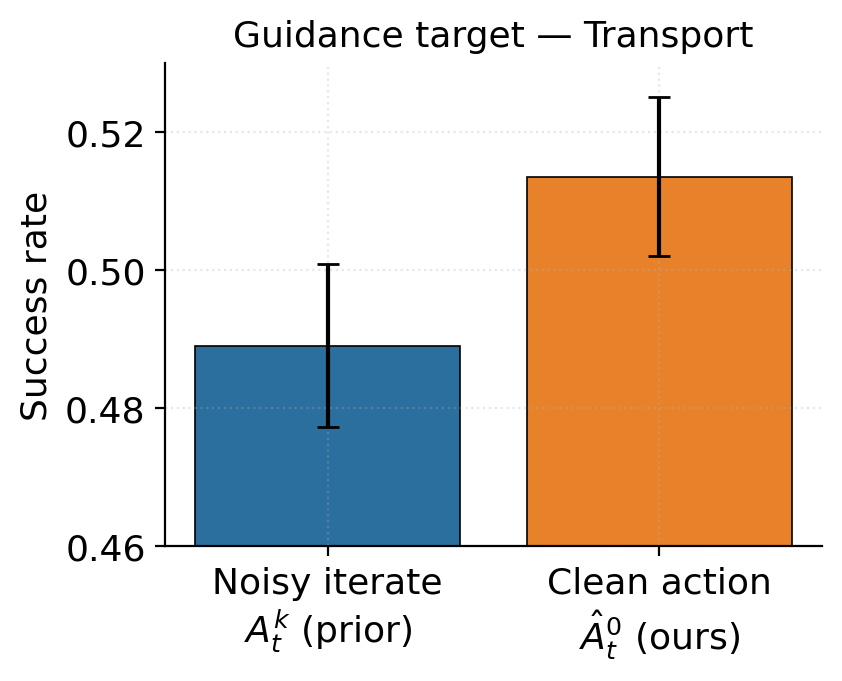
corrective rollouts: it constructs phase-specific latent targets, applies guidance only in the
drifted-but-recoverable regime, and guides through the estimated clean action to match the
dynamics model's training distribution. Successful guided rollouts are then absorbed back into
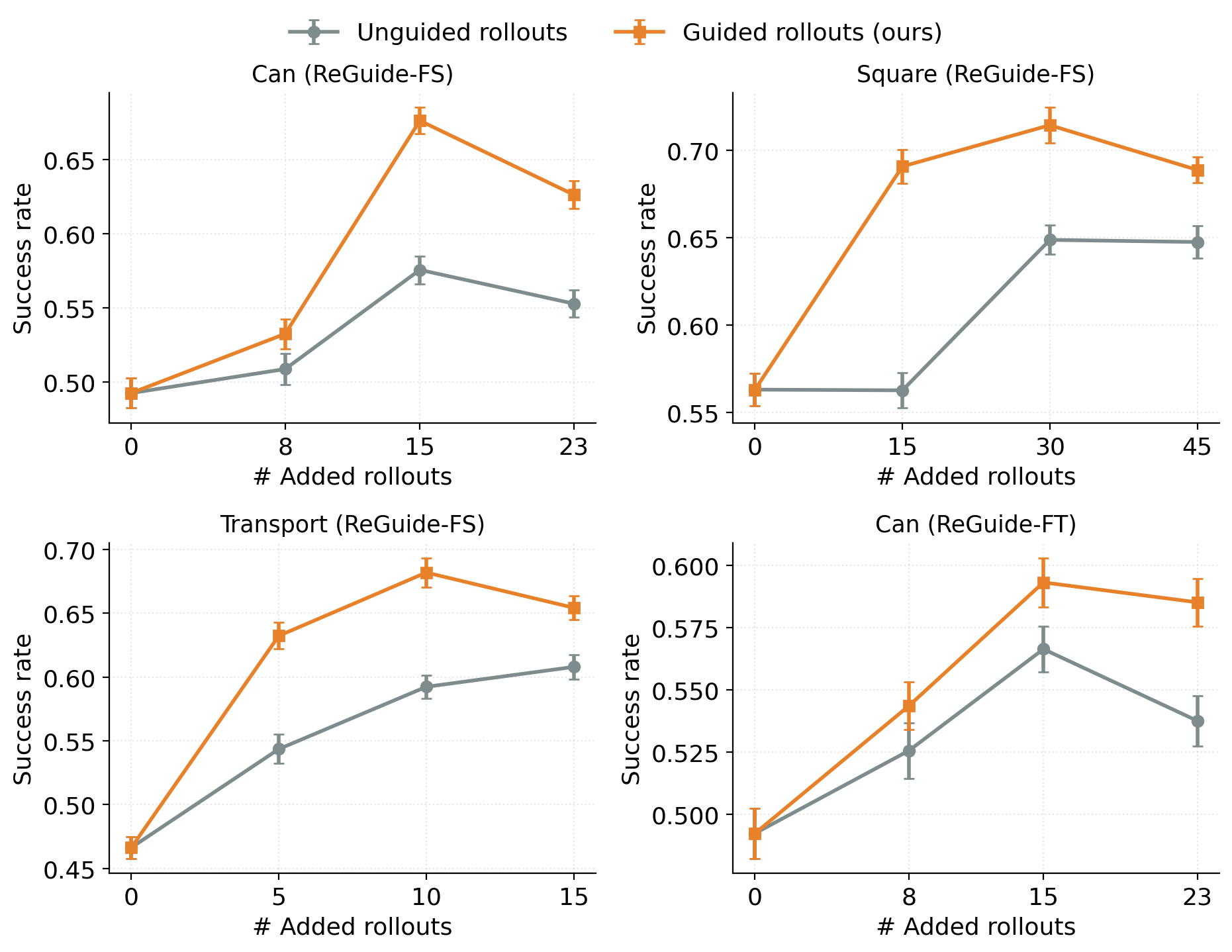
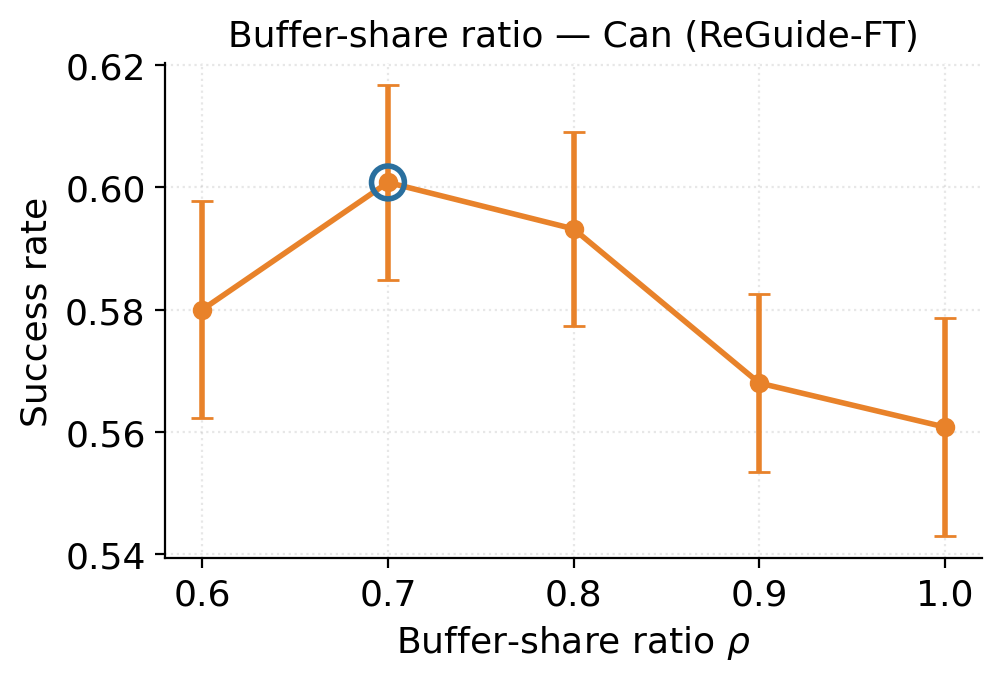
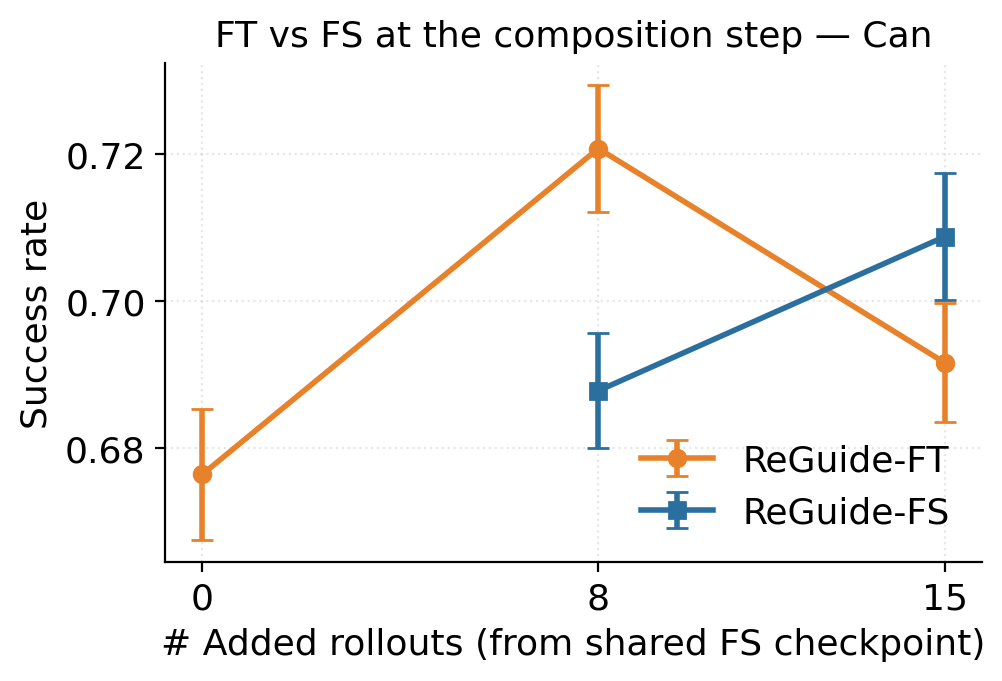
the policy through ReGuide-FT, which fine-tunes the current checkpoint, or
ReGuide-FS, which retrains from scratch on the augmented dataset; the two can also be
composed and iterated.
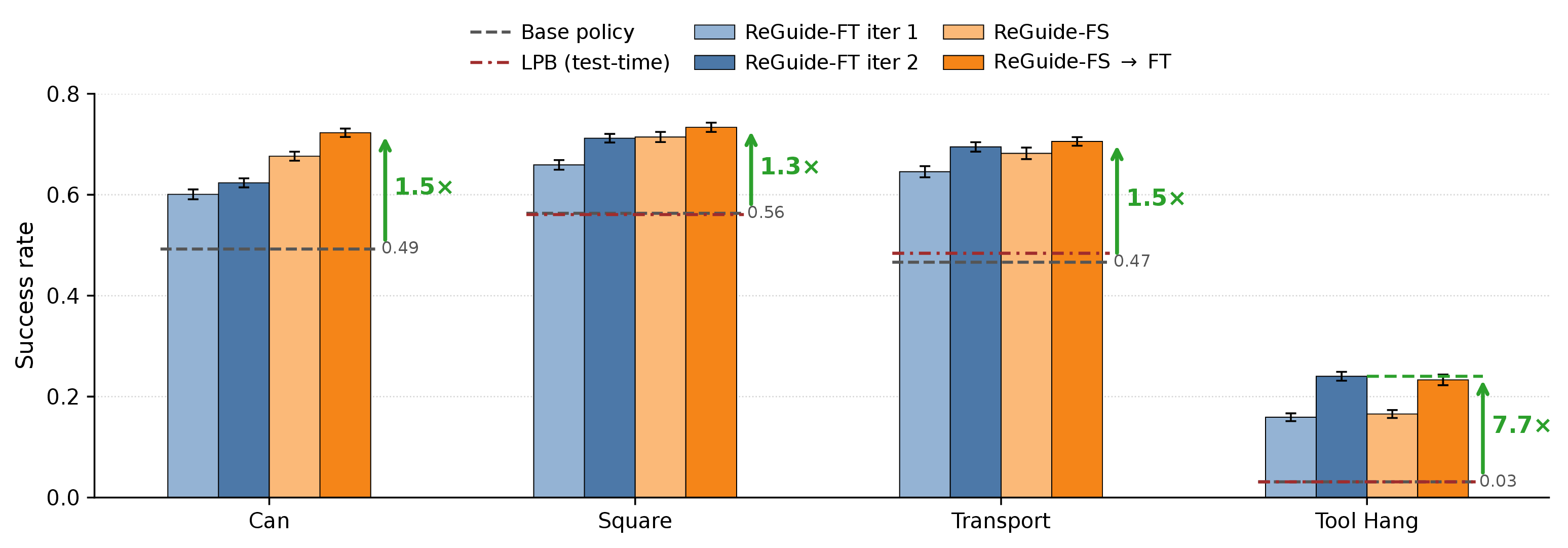
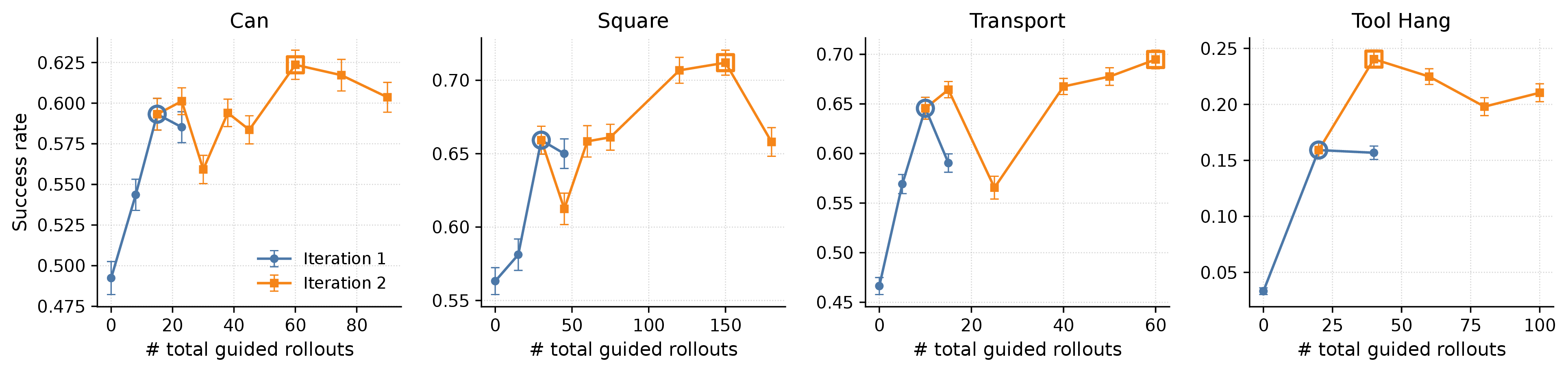
On Robomimic Can, Square, Transport, and Tool Hang, ReGuide improves base-policy success by
1.3–7.7×, outperforms LPB in the test-time-only setting, and matched-data
ablations show that the gains come from guided recovery data rather than additional rollouts alone.